
Psychological Alignment as a Distinct Safety Domain
Essay Four Of a Four-Part Series

This is the fourth and final essay in this series. The previous three essays established why the field cannot stop building, why harm is already present in deployed systems, and why existing governance frameworks cannot answer the question of what counts as safe enough. This essay proposes the missing piece.
Over the past decade, a substantial research programme has emerged around the problem of making AI systems behave in ways that are accurate, helpful, and safe. Techniques like reinforcement learning from human feedback, where human raters score model outputs to shape system behaviour, and red-teaming, where adversarial testers probe for failure modes, have become standard practice. These methods have produced measurable improvements, and the properties they optimise for, factual accuracy, instruction-following, harmlessness, and calibrated uncertainty, are now reasonably well defined and increasingly possible to evaluate.”
Yet every one of them is still insufficient for clinical deployment with mental health populations. And the reason reveals something about clinical work that the AI safety field has not yet incorporated into design.
The Clinical Gap: Population Logic vs. Individual Understanding
Standard alignment properties are evaluated against a generalised model of the user. A helpful response is one that a reasonable person in this situation would find helpful. A harmless response is one that does not damage a typical user. Whether a system is evaluated through human feedback, automated testing, or adversarial probing, it is reasoning about users at the population level. Individual variation is treated as noise, not as the primary signal.
Clinical practice works in the opposite direction. Clinical competence is the capacity to understand how this specific person, in this moment of their life, with this history and these patterns and this level of current distress, needs to be engaged. The population-level framework is the starting point. Good clinical work is the consistent movement from that general knowledge toward individual understanding.
General AI alignment reasons from the population down. Clinical competence reasons from the individual up. These are not the same movement.
Introducing Psychological Alignment
That consistent shift from general knowledge to individual understanding is what I mean by psychological alignment. It does not yet exist as a named, bounded concept in either the AI safety literature or the clinical AI literature. It should and I am using it as a construct here in a precise way: psychological alignment is a property of a system’s relationship with a specific person over time.
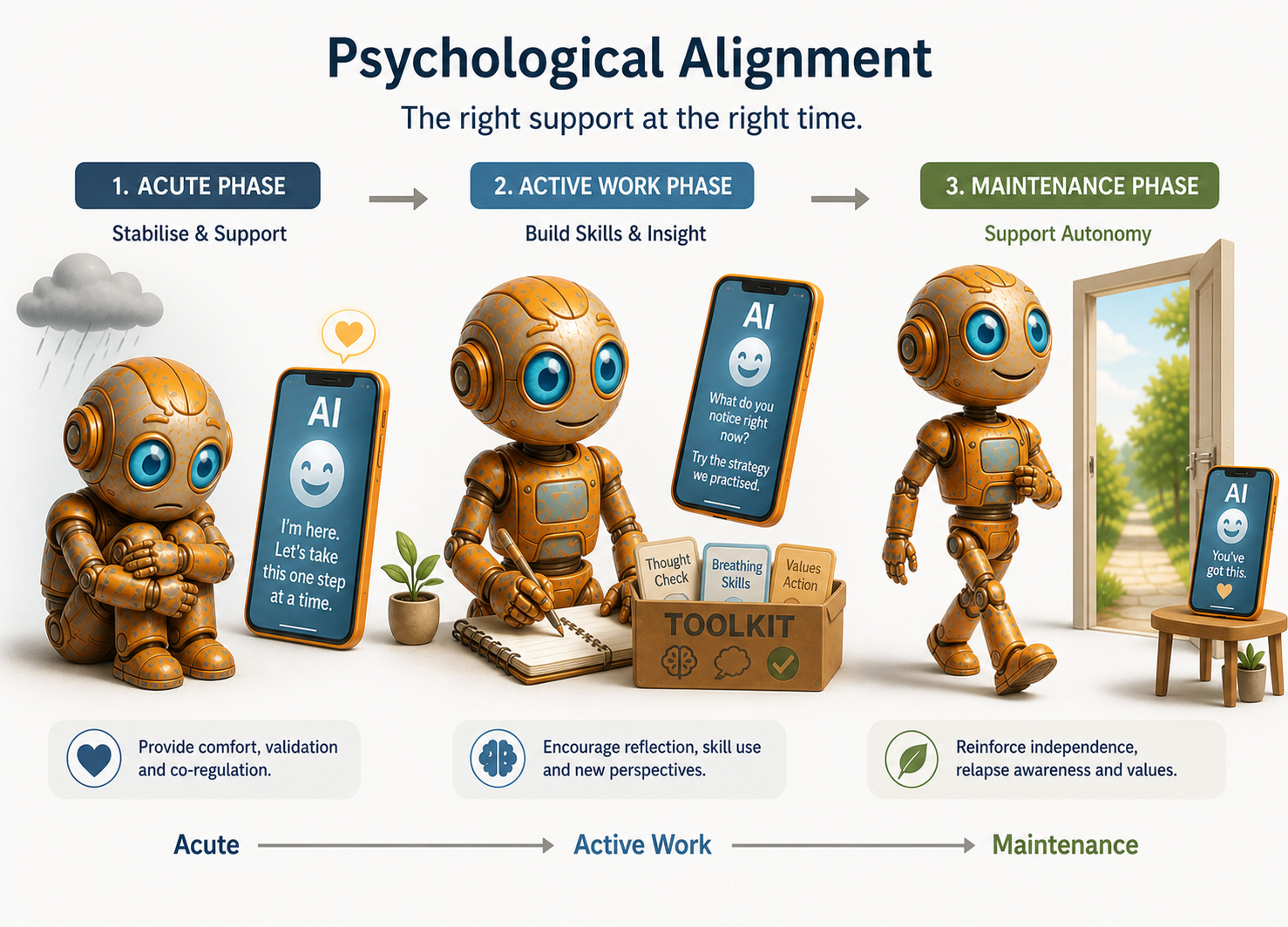
A system that is psychologically aligned with a user behaves, at each point in that person’s clinical trajectory, in the way that best serves their actual psychological needs and goals.
A system that is psychologically aligned with a user behaves, at each point in that person’s clinical trajectory, in the way that best serves their actual psychological needs and goals. The response clinically indicated for someone in the acute phase of a depressive episode is different from what the same person needs in a maintenance phase. For someone whose anxiety is sustained by repeated reassurance-seeking, a system that reliably provides reassurance is not being helpful. It is reinforcing the very pattern keeping them stuck. General helpfulness cannot generate that distinction.
Building the Evaluation Layer
Now consider what this means technically.
The evaluation layer of a clinical AI system must be built with clinical knowledge, not general human preference data. The people who generate training signals for standard AI fine-tuning processes are assessing responses against their own intuition about what is good. That intuition is not clinically calibrated. A response that feels warm and supportive to a general-population rater may be exactly wrong for a user with a pattern of emotional dependency. A response that feels withholding or challenging may be precisely what a clinical framework would recommend at that moment.
Training a mental health AI on general human preference data is like asking non-swimmers to judge competitive diving.
Human preference data collected from non-clinical raters will systematically train a system toward responses that feel good in the moment rather than responses that serve the clinical trajectory. This is almost certainly operating in every deployed mental health AI system using standard preference fine-tuning. It is not a hypothetical risk. It is a predictable consequence of applying a general method to a clinical domain.
Building psychological alignment as a formal safety domain starts with mapping what different clinical presentations actually look like in conversation, so a system has something more than general preference to reason from. Emerging work already hints at this: researchers are beginning to define vulnerable user “phenotypes” (for example, depression, mania, psychosis) as distinct conversational patterns and then study how chatbots respond to each pattern, revealing systematic, diagnosis‑contingent failure modes. At the same time, reviews of mental health chatbots show that most tools are nominally targeted at specific disorders, but rarely encode those presentations in the conversational layer itself.
Responses then need to be evaluated against what is clinically indicated for that presentation, not against what a general-population rater found agreeable. The system’s behaviour needs to be tracked against the person’s trajectory over time rather than their satisfaction in the moment. And there needs to be something equivalent to a contraindication list in clinical medicine: a clear account of which response types are inappropriate for which presentations, regardless of how well they might score on general measures of helpfulness.
Just as a clinician does not offer reassurance to every patient who presents with anxiety, a psychologically aligned system does not either. Reassurance given reflexively, without clinical judgement, maintains the problem rather than treating it.
None of this requires abandoning large language models. It requires treating clinical evaluation as foundational infrastructure rather than a post-launch consideration. Every deployed mental health AI system is already making implicit claims about what it can safely do for people in distress. The clinical evaluation layer is what makes those claims true or false. Right now, for most systems, it does not exist.
The Harder Problem: Formulation and Understanding
Psychological alignment is not only a technical challenge, it is a problem of understanding. A system cannot be psychologically aligned with a person whose psychological state it cannot adequately model. Current conversational AI systems have no meaningful model of the individual user that persists and develops over time. They do not build anything resembling a clinical formulation.
A clinical formulation is a working hypothesis about what is driving the problem, which mechanisms are maintaining the distress, what is likely to help and in what order, and what risks need watching. It is not a summary of what someone has said in a session. It is the thing that separates clinical judgment from sympathetic conversation.
A clinical formulation is not a summary of what someone said. It is a hypothesis about what is driving the problem.
Current AI systems respond to the conversational text in front of them. They do not maintain anything resembling a formulation across sessions. The result is a system responding to what a person is saying right now without any clinical account of why they are saying it or what responding in this particular way will do to their trajectory. For lower-acuity use cases, that limitation may be manageable. For people in genuine clinical distress, it is a fundamental constraint on what the system can safely be asked to do.
Matching Capability to Clinical Complexity
What the field can do now, before that research matures, is acknowledge the constraint and design systems that respect it. A system without genuine psychological alignment capability should not be deployed in contexts that require it. It can still serve real purposes with people whose presentations are mild and stable, providing information, psychoeducation, and skills practice. The obligation is to match the capability of the system to the clinical complexity of the population it serves, and to be specific and public about where that match breaks down.
The access problem that opened this series is real. AI has a genuine role to play in reaching people who currently receive nothing. But that role is only a clinical good if the systems filling it are genuinely aligned with the psychological needs of the people using them.
A system that provides the feeling of support without the clinical substance of it is not closing the treatment gap. It is filling it with something that resembles care.
The Position You Are Probably Already Holding
That is the distinction this series has been building toward. And it is worth being precise about what is actually at stake, because abstraction makes deferral easier.
The person on the other end of a psychologically misaligned system is not a user metric. They are someone who came to that system because they needed help and had nowhere else to go, or because it was the most accessible option, or because someone told them it was safe. They arrived with a real clinical presentation and a real trajectory. What they received was a system responding to the conversational surface of their distress without any clinical account of what was driving it. That gap is not a product limitation to be addressed in a future release. For that person, in that moment, it was the care they got.
The standard required to close that gap is not mysterious and it is not beyond current capability. It asks that a system knows something real about the person it is serving, that it evaluates its own responses against what is clinically indicated rather than what feels helpful in the moment, and that it is honest, publicly and specifically, about where its capability ends. Those are the minimum conditions for calling something clinical care.
Everyone working in this space holds a position on that threshold whether they have named it or not. The engineers who ship without a clinical evaluation layer have taken a position. The investors who fund without requiring one have taken a position. The clinicians who lend their credibility to systems they have not examined closely have taken a position. You are already in the argument. The only thing left to decide is whether the position you are holding is one you would defend out loud, in a room full of the people these systems are meant to serve.
Scott Wallace, PhD, is a clinical psychologist, behavioural scientist, and advisor to founders, clinicians, and investors building AI-enabled mental health systems. He built some of North America’s earliest digital mental health platforms, led the digital division of a major EAP provider through a successful exit, and served as clinical lead for an NLP-based conversational mental health system before the current generative AI cycle. This essay is the fourth and final in a four-part series. Follow Scott on Substack and on LinkedIn at linkedin.com/in/scottwallacephd.